Download the notebook here!
Interactive online version: ![]()
[1]:
import sys
import respy as rp
import numpy as np
sys.path.insert(0, "python")
from auxiliary import plot_observed_choices # noqa: E402
from auxiliary import plot_time_preference # noqa: E402
from auxiliary import plot_policy_forecast # noqa: E402
Structural microeconometrics
Computational modeling in economics
provide learning opportunities
assess importance of competing mechanisms
predict the effects of public policies
Eckstein-Keane-Wolpin (EKW) models}
understanding individual decisions
human capital investment
savings and retirement
predicting effects of policies
welfare programs
tax schedules
Components
economic model
mathematical formulation
calibration procedure
Economic model
Decision problem
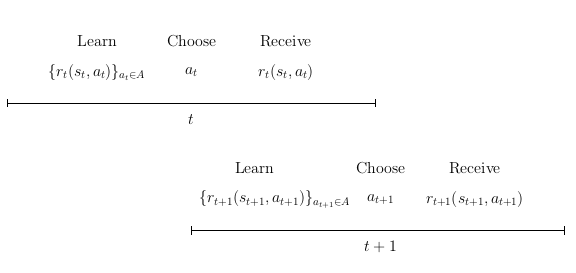
Individual’s objective
Mathematical formulation
Policy evaluation
Inductive scheme
Optimality equations

Calibration procedure
Data
\(s_t = (x_t, \epsilon_t)\)
\(x_t\) observed
\(\epsilon_t\) unobserved
Procedures
likelihood-based
\[\hat{\theta} \equiv argmax_{\theta \in \Theta} \prod^N_{i= 1} \prod^{T_i}_{t= 1}\, p_{it}(a_{it}, r_{it} \mid x_{it}, \theta)\]simulation-based
\[\hat{\theta} \equiv argmin_{\theta \in \Theta} (M_D - M_S(\theta))' W (M_D - M_S(\theta))\]
Example
Seminal paper
Keane, M. P., & Wolpin, K. I. (1994). The solution and estimation of discrete choice dynamic programming models by simulation and interpolation: Monte Carlo evidence. Review of Economics and Statistics, 76 (4), 648–672.
Model of occupational choice
1,000 individuals starting at age 16
life cycle histories
school attendance
occupation-specific work status
wages
Labor market
The same setup applies to the second occupation.
Schooling
Home
State space
Transitions
observed state variables
\[\begin{split}e_{1,t+1} = e_{1t} + I[\,a_t = 1\,] \\ e_{2,t+1} = e_{2t} + I[\,a_t = 2\,] \\ g_{t+1} = g_{t\phantom{2}} + I[\,a_t = 3\,]\end{split}\]unobserved state variables
\[\{\epsilon_{1t},\epsilon_{2t},\epsilon_{3t},\epsilon_{4t}\} \sim N(0, \Sigma)\]
[2]:
params, options = rp.get_example_model("kw_94_two", with_data=False)
How is the economy parametrized?
[3]:
params.head()
[3]:
| value | comment | ||
|---|---|---|---|
| category | name | ||
| delta | delta | 0.9500 | discount factor |
| wage_a | constant | 9.2100 | log of rental price |
| exp_edu | 0.0400 | return to an additional year of schooling | |
| exp_a | 0.0330 | return to same sector experience | |
| exp_a_square | -0.0005 | return to same sector, quadratic experience |
How are the options set?
[4]:
options
[4]:
{'estimation_draws': 200,
'estimation_seed': 500,
'estimation_tau': 500,
'interpolation_points': -1,
'n_periods': 40,
'simulation_agents': 1000,
'simulation_seed': 132,
'solution_draws': 500,
'solution_seed': 1,
'monte_carlo_sequence': 'random',
'core_state_space_filters': ["period > 0 and exp_{choices_w_exp} == period and lagged_choice_1 != '{choices_w_exp}'",
"period > 0 and exp_a + exp_b + exp_edu == period and lagged_choice_1 == '{choices_wo_exp}'",
"period > 0 and lagged_choice_1 == 'edu' and exp_edu == 0",
"lagged_choice_1 == '{choices_w_wage}' and exp_{choices_w_wage} == 0",
"period == 0 and lagged_choice_1 == '{choices_w_wage}'"],
'covariates': {'constant': '1',
'exp_a_square': 'exp_a ** 2',
'exp_b_square': 'exp_b ** 2',
'at_least_twelve_exp_edu': 'exp_edu >= 12',
'not_edu_last_period': "lagged_choice_1 != 'edu'"}}
We can now simulate a dataset and look at the individual decisions.
[5]:
simulate_func = rp.get_simulate_func(params, options)
plot_observed_choices(simulate_func(params))

Mechanisms
[6]:
def time_preference_wrapper_kw_94(simulate_func, params, value):
policy_params = params.copy()
policy_params.loc[("delta", "delta"), "value"] = value
policy_df = simulate_func(policy_params)
edu = policy_df.groupby("Identifier")["Experience_Edu"].max().mean()
return edu
Now we can iterate over a grid of discount factors.
[7]:
deltas = np.linspace(0.945, 0.955, 10)
edu_level = list()
for i, delta in enumerate(deltas):
stat = time_preference_wrapper_kw_94(simulate_func, params, delta)
edu_level.append(stat)
plot_time_preference(deltas, edu_level)

Policy forecast
[8]:
def tuition_policy_wrapper_kw_94(simulate_func, params, tuition_subsidy):
policy_params = params.copy()
policy_params.loc[("nonpec_edu", "at_least_twelve_exp_edu"), "value"] += tuition_subsidy
policy_df = simulate_func(policy_params)
edu = policy_df.groupby("Identifier")["Experience_Edu"].max().mean()
return edu
Now we can iterate over a grid of tuition subsidies.
[9]:
subsidies = np.linspace(0, 1500, num=10, dtype=int, endpoint=True)
edu_level = list()
for i, subsidy in enumerate(subsidies):
stat = tuition_policy_wrapper_kw_94(simulate_func, params, subsidy)
edu_level.append(stat)
plot_policy_forecast(subsidies, edu_level)
